It’s out! OpenCV 5 has officially been released, and honestly, this one feels like a bigger deal than most people might realize at first glance.

I have a special relationship with this library. I started using OpenCV back in the early 2000s, during its beta versions, when the API was pure C and the documentation was sparse. I picked it up while writing my laurea degree thesis, and it immediately became the tool I relied on for everything vision-related. Over the following years, I watched it evolve from that original C interface, through the C++ rewrite that made it actually pleasant to use, through the Python bindings that brought it to an entirely new audience, and through the deep learning integration in the 4.x era. It’s a library I’ve grown up with professionally, and every major release carries a bit of that history.

So yes, this announcement landed differently for me than just another library update. OpenCV is one of those tools you just take for granted; it’s been the backbone of computer vision projects for over two decades, and this major version bump is the largest leap the project has taken in a long time.
The official launch happened at CVPR 2026 in Denver on June 4th, with the pip package following on June 8th. And honestly, coming just two weeks after ROS 2 Lyrical Luth, this is shaping up to be quite a season for open-source robotics and computer vision. Two major releases in less than a month; I’ll happily take it.
Given how important OpenCV is to me, I read through the full announcement pretty carefully, and there’s a lot to unpack.
The DNN engine rewrite: the headline feature
If there is one thing that defines this release, it’s the complete redesign of the deep learning inference engine. The old DNN module in OpenCV 4.x was functional but limited; ONNX operator coverage sat at around 22%, which meant you constantly ran into missing ops when trying to load modern models. OpenCV 5 brings that number to 80%+. That is not an incremental improvement; that is a fundamental change in what you can actually run with OpenCV out of the box.

The new engine is graph-based, with proper shape inference, constant folding, dynamic shape support, and even control flow through If/Loop subgraphs. It also handles quantized models natively and includes attention fusion using FlashAttention-style optimizations. This is a serious piece of engineering.
Three engines for a smooth transition
One of the smartest decisions the team made was keeping backward compatibility through a three-tier engine selection model, exposed via the EngineType enum:
ENGINE_CLASSIC is the original 4.x engine, preserved for non-CPU backend support. ENGINE_NEW is the new graph-based engine, currently CPU-only. ENGINE_AUTO is the default: it tries the new engine first and falls back to classic when needed. There’s also ENGINE_ORT, an optional wrapper around ONNX Runtime for cases where you want to delegate to that backend explicitly.
This is a thoughtful migration path. You get the new engine’s benefits immediately for supported models, and nothing breaks for everything else. I can already imagine how many CI pipelines would have exploded otherwise.
LLM and VLM support, natively
This one genuinely surprised me. OpenCV 5 can now run large language models and vision-language models natively, with a built-in tokenizer (no external dependency), KV-cache for autoregressive decoding, and support for Qwen 2.5, Gemma 3, PaliGemma, and the GPT family. The team reports token-for-token accuracy matching ONNX Runtime. Running a VLM from OpenCV directly is not something I expected to see in 2026, but here we are.

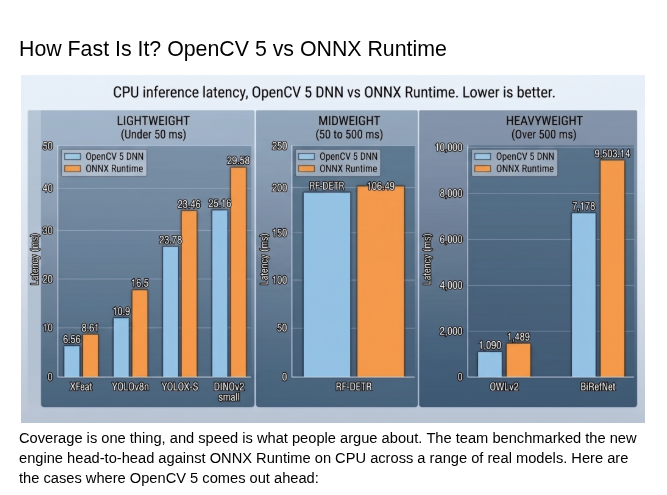
Performance numbers
The team benchmarked the new engine against ONNX Runtime on an Intel Core i9-14900KS, and the results are worth quoting: XFeat is 31.25% faster, YOLOv8n is 11.5% faster, OWLv2 is 36.6% faster, and BiRefNet is 32.4% faster. These are real workloads, not toy benchmarks.
New data types and core improvements
OpenCV 5 adds native FP16 (cv::hfloat) and BF16 (cv::bfloat) support, which is long overdue. Working with neural network outputs in deep learning pipelines has always required manual conversion steps; having these types first-class in cv::Mat makes the whole thing significantly cleaner.
There’s also support for 0D (scalar) and 1D tensor representations, proper broadcasting operations, and new 64-bit integer and boolean types. The library is finally catching up to how modern ML frameworks represent data, which matters a lot when you’re gluing OpenCV preprocessing together with PyTorch or ONNX models.
On raw performance: the team reports up to 2x improvements on mathematical workloads and 3 to 4x speedups on ARM for operations like resizing and warping. The Universal Intrinsics layer has been updated to v2.0 with support for SSE, AVX2/512, NEON, SVE, and RISC-V Vector. This is great news for anyone running embedded vision on ARM boards.
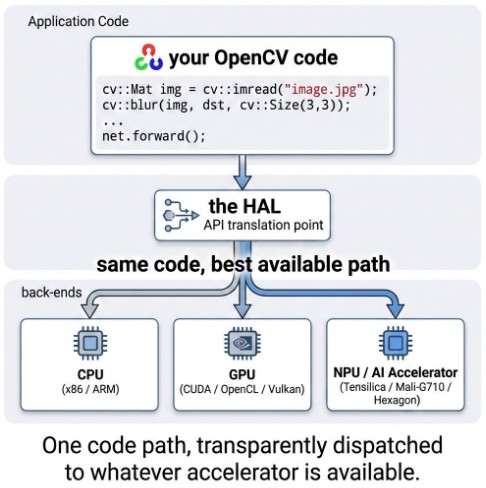
Hardware Acceleration Layer (HAL)
This is a feature that I think will have a big long-term impact: OpenCV 5 introduces an automatic dispatch mechanism to vendor-optimized kernels through a Hardware Acceleration Layer. Currently supported backends include Intel IPP (IPPICV) for x86/x64 with SSE/AVX, Arm KleidiCV for AArch64, Qualcomm FastCV for Snapdragon/Hexagon DSP, and RISC-V Vector extensions. The dispatch is automatic; the same OpenCV code just runs faster on each platform.
For robotics and edge deployments, this is a big deal. You write once and the library adapts to the hardware underneath without any extra configuration.
3D vision: a long-overdue reorganization
This section is personally very relevant to my work. The calib3d module, which had grown into a bloated catch-all over the years, has been split into three focused modules:
3d covers geometry, I/O, ICP, and SLAM components. calib handles single and multi-camera calibration, including hand-eye and robot-world calibration. stereo covers depth estimation from stereo pairs.
The new calibrateMultiview API for multi-camera setups, point cloud and mesh I/O for OBJ and PLY formats, dense RGB-D fusion with TSDF, HashTSDF, and ColorTSDF, and the USAC framework with MAGSAC robust estimation are all welcome additions. At Stereolabs, we deal with 3D reconstruction and depth pipelines every day; a well-structured API for these building blocks makes a real difference.
Features module: deep learning meets classic detectors
The features2d module has been replaced by a new features module that brings deep learning-based detection and matching alongside the classic detectors we know and love.
New additions include ALIKED (a CNN-based keypoint detector and descriptor), DISK (reinforcement learning features designed for wide-baseline matching), and LightGlueMatcher (an attention-based matcher with confidence-scored correspondences). Classic detectors like SIFT, ORB, and FAST are retained for backward compatibility, so nothing breaks if you’re not ready to migrate.
The combination of learned features with the classic OpenCV pipeline architecture is interesting; I’m curious to see how ALIKED and LightGlueMatcher perform on real-world robotics sequences versus standard benchmarks.

Generative models in OpenCV
I wouldn’t have predicted this one a couple of years ago. OpenCV 5 ships with LaMa inpainting for mask-guided object removal and a diffusion-based inpainting pipeline as a second option. This feels a bit out of scope for a library historically focused on classical and discriminative vision, but given where the field has gone, I understand the push. It makes OpenCV more self-contained for demo and prototyping use cases.

Python and C++ improvements
On the Python side: NumPy 2.x support is here at last, named (keyword) arguments work properly for algorithm classes, and the bindings have been modernized throughout. If you’ve spent time fighting NumPy deprecation warnings in OpenCV, this update is for you.
On the C++ side: C++17 is now the minimum recommended standard, with C++20 modules planned for later 5.x releases. The legacy C API (the old cvXxx function style) is officially deprecated in this release. It’s been a long time coming; the C API has been a maintenance burden and a source of confusion for newcomers for years.
The documentation has also been migrated from Doxygen to Sphinx + Doxygen, with persistent navigation, hand-written tutorials alongside the API reference, and Python and C++ signatures shown together. A small change in appearance, but a big improvement in day-to-day usability.
What’s coming next in the 5.x cycle
The work isn’t done. The team has committed to GPU acceleration for the new DNN engine (CUDA and TensorRT), a non-CPU HAL for accelerated pre/post-processing that avoids GPU-to-CPU round trips during inference, and C++20 module support. These are the pieces that will make OpenCV 5 really complete for production deep learning pipelines; right now the new engine is CPU-only, which limits where you’d actually deploy it.
Final thoughts
OpenCV 5 is a real release. The DNN engine rewrite alone would justify a major version bump; everything else on top, the HAL, the 3D reorganization, the new data types, and the Python modernization, makes this feel like the library catching up to where the field has been for the past few years. The ~1 million daily installs figure and 86,000+ GitHub stars show how many projects still depend on it; this update will have a wide impact.
If you’re maintaining a computer vision pipeline that uses OpenCV’s DNN module, this is the time to start testing. The ENGINE_AUTO default means migration should be smooth for most cases, but it’s worth validating explicitly rather than assuming. The full OpenCV 5.0 documentation is the best place to start.
Happy robotics programming… with vision! 🤖